This is like Unix tools but distributed across thousands of machines. Instead of the stdin and stdout like Unix, map reduce jobs read and write files on a distributed filesystem like the Hadoop File System with the goal of process large datasets.
Pattern
- Read a set of input files and break into records
- Call mapper to extract key and value from each input record
- Sort all key-value pairs by key
- Call reducer to iterate over sorted key-value pairs. If there are multiple occurrences of the same key, it is easy to combine these values since they are adjacent
Mapper
The mapper is called once for every input record and its job is to extract the key and value from the input record. For each input, it may generate a number of key value pairs. This is stateless.
Reducer
The MapReduce framework takes the key-value pairs, collects all the values belonging to the same key, and calls the reducer with an iterator over that collection of values. The reducer can produce output records.
The scheduler tries to run the mapper on the machine that has a replica of the input file to prevent copying the file over a slow network. A hash of a key is used to make sure that all key-value pairs with the same key end up at the same reducer.
It is very common for MapReduce jobs to be chained together into workflows, where the output of one job becomes the input to the next job.
Tools
Schedulers
- Oozie
- Azkaban
- Luigi
- Airflow
- Pinball High level tools
- Pig
- Hive
- Cascading
- Crunch
- FlumeJava
Note
At a high level, this kind of feels like how CUDA Kernels work. The map phase feels the same as writing a kernel.
Often times, we need to span multiple tables (files) to collect all the information that we care about, meaning that we need to merge on some key at some point. The most efficient way to do this is to take a copy of a database and put it on the same distributed filesystem as the other table and use MapReduce to bring together the relevant records. This example is of a reduce-side join which is easier since we don’t need to make assumptions (size, sorting, partitioning) but is more costly than a map-side join which we can only do if we can make assumptions about our input records which are faster and do not require reducers or sorting to join our tables.
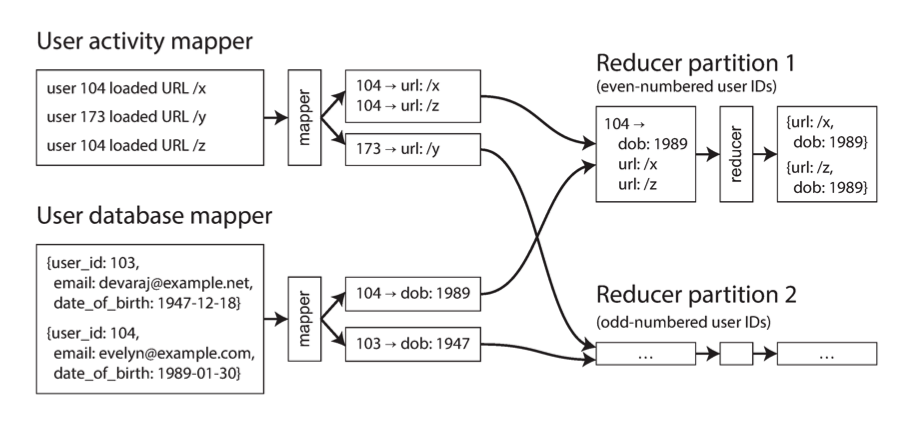
You can perform other operations that are available in other data processing tools:
- Groupings and aggregations
Skew
Different MapReduce tools handle skew in hotspots in different ways. This occurs since reducers are deterministic. Solutions include, randomly assigning reducers and manually determining hotspots.
Map Reduce was made by Google for their batch jobs that were at risk of being pre-empted by higher priority tasks. Therefore it made sense that Map Reduce was designed to be fault tolerant due to the frequency of unexpected task termination (50%). Today this type of task preemption is less widely used and the design decisions of MapReduce make less sense (the cost of overhead in terms of scheduling overhead, disk IO, and the network shuffle, to the benefit of fault tolerance and parallelization). To fix the problems associated with map reduce, new execution engines like Spark were developed which handle an entire workflow as one job rather than independent subjobs.