Suitable for applications that require a series of independent computations to be performed on a stream of data.
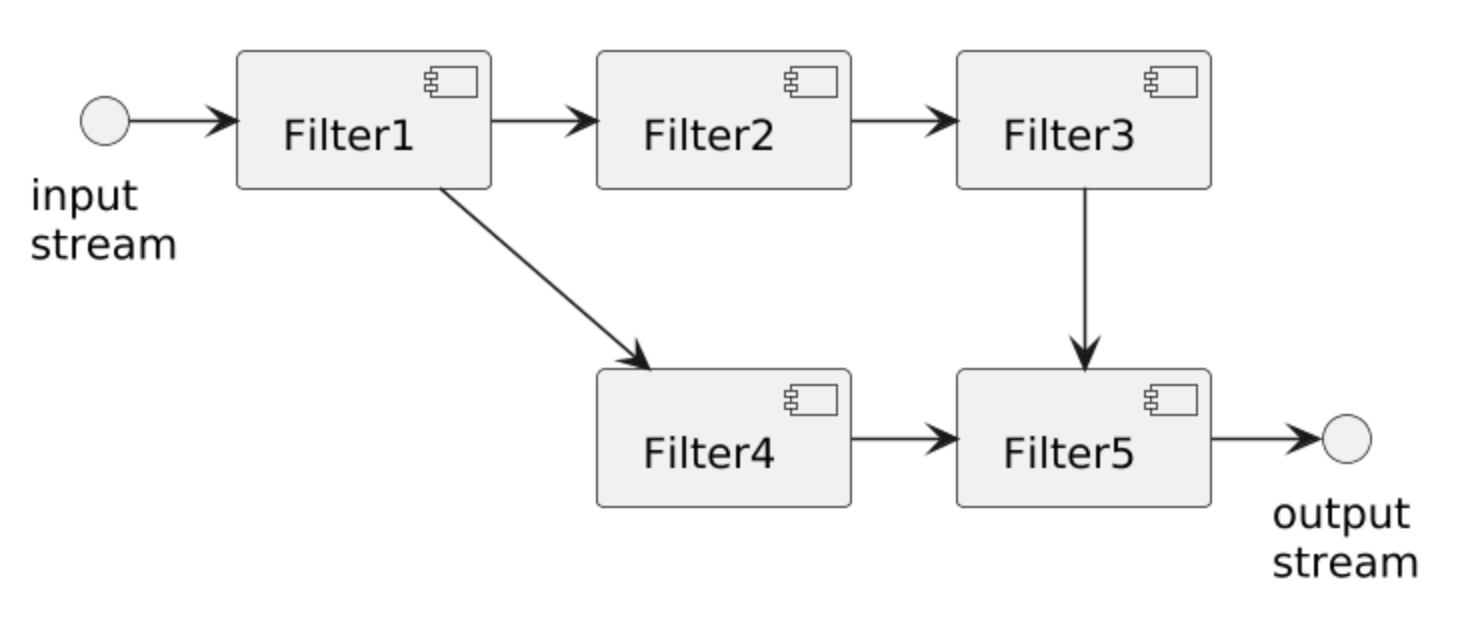 Consists of:
Consists of:
- Filters
- Transforms data input to data output
- No shared state between filters (Pure Functions)
- Outputs can begin when all inputs are consumed
- Pipes:
- Carry data between filters
Pros and Cons
Pros:
- Filters can be replaced or improved locally as long as contracts remain the same
- Supports concurrency naturally through parallelization
- Performing throughput and deadlock analysis is possible Cons:
- Deserialization across pipes can be expensive
- Adding pipe variants adds complexity
- Debugging end to end behaviours can be non-trivial
- Not ideal for interactive systems
Variants
Pipelines:
- Requires a linear sequence of filters, where each filter is responsible for its own domain (each components)
- See
|in unix shells Batch-Sequence: - Based on the pipeline variants, requires that each filter processes all input before producing output
An important example is distributed data processing systems which use pipe filters to perform a graph of transformations across a large dataset. This includes Map Reduce.