Less fast, expensive and larger than Registers but faster, more expensive and smaller than RAM.
You want to use a cache like Redis when you have data that is expensive or slow to retrieve. Precomputing things is a good place to use a cache.
By using a cache, there is an implicit understanding that the data being read is somewhat stale and therefore, cannot be strongly consistent.
Quote
The hardest things in Computer Science are:
- Cache invalidation
- …
Write-Behind
- Service writes to cache
- Worker reads pending items and writes to DB
- After DB write remove item from cache The downsides here are if Redis dies before all data is written to DB, data is lost.
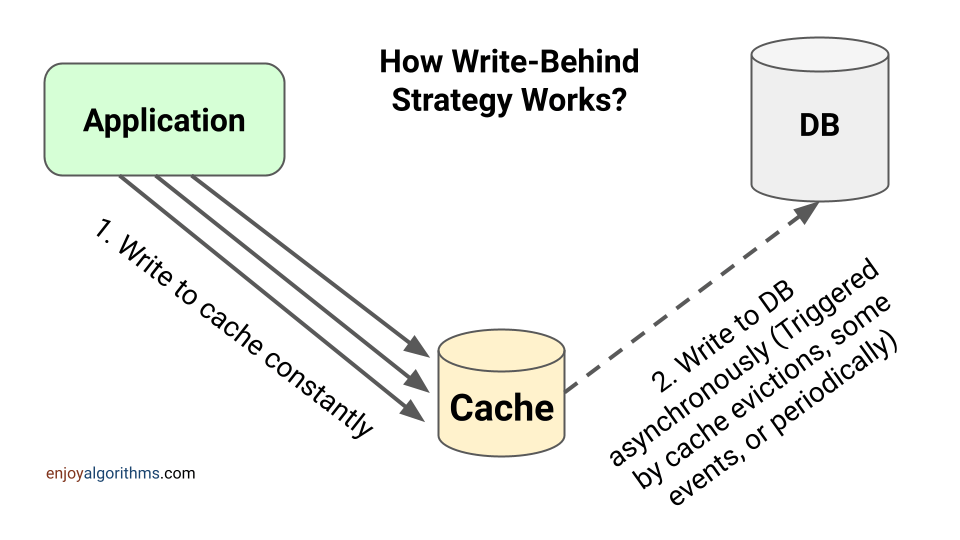
This is what I intuitively thing of for write-heavy workloads but using a Message Queue might be better.
In a systems sense
The goal here is to delay a write to memory from as long as possible. We have 3 states here:
- Modified: Only this cache has a valid copy
- Shared: location is unmodified
- Invalid: Out of date
This implementation writes data to memory if another processor requests it.
Write-Through
Write to the cache and persistent storage at the same time. Reads are very fast here. This also helps with data recovery.
There are 2 states (valid, invalid), for each memory location. Events are either from a processor or the bus. If you see a bus write, you are invalid, otherwise you are valid (even if you write since you know the state of the new value).
Cache Misses
The CPU generates a memory address for each read or write operation which is mapped to a page which is ideally found in the cache. If it is found, we have a cache hit, otherwise a cache miss. If we cache miss, we need to load the page from memory which is a slow operation. The effective access time is computed as where h is the hit ratio, is the time required to load a page from the cache, and is the amount of time it would take to load the page from memory.
Levels
Caches have levels which are their distance from the CPU:
- L1 (fastest)
- L2
- L3 (slowest) We check each cache as we go towards main memory and propagate pages upwards if they are found at a cache level.
If we replace the time to retrieve from memory with the time to retrieve from disk, and redefine the hit ratio as the chance a page is in memory, we can get the effective access time for virtual memory: . Now we can combine these two definitions to get the true effective access time when there is only one level of cache:
.
The time it takes to load a page from disk is a slow step here which is several orders of magnitude larger than any of the other costs in the system. Thus dominates the equation. If a page fault rate is high, performance is awful, therefore, misses are not just expensive, but impact performance more than anything else.