The typical boring standard uniprocessor is the Single Instruction Single Data processor where the Ml in modern processors stands for multiple.
Overview:
- You can load a bunch of data and perform arithmetic
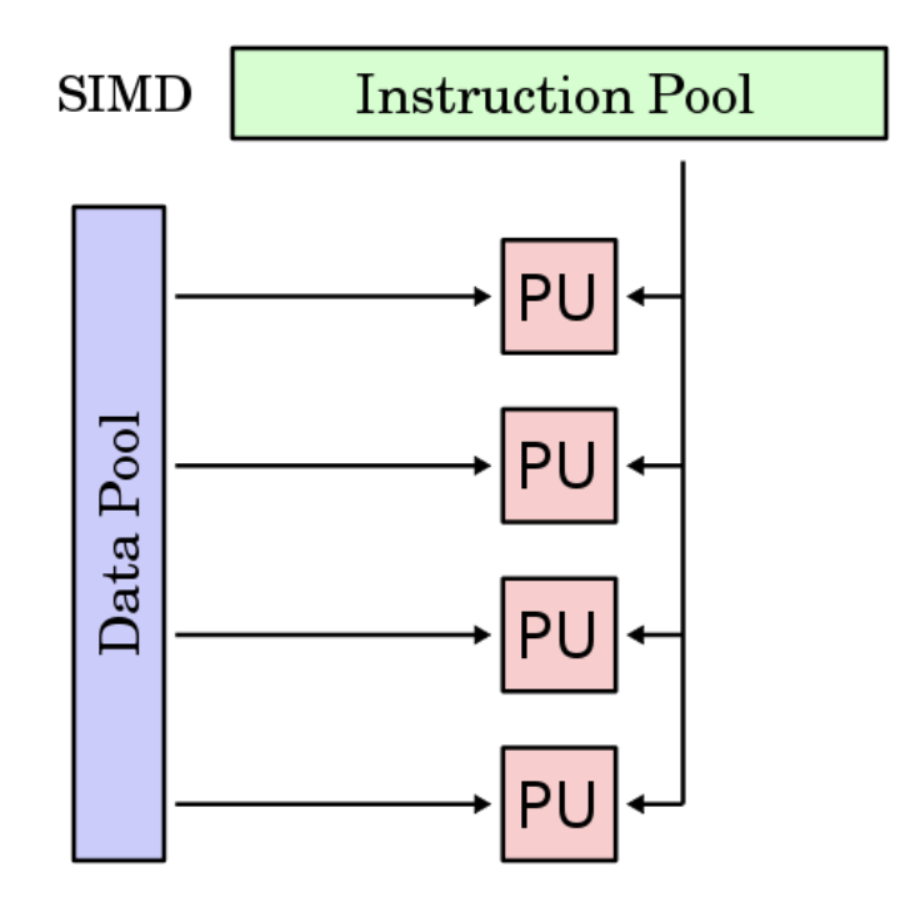
- Instructions process multiple data items simultaneously SIMD provides an advantage by using a single control unit to command multiple processing units, this reduces the amount of overhead in the instruction stream.
We can basically use this instead of Threads and compile using rustc defaults to get core loop contents if we try to parallelize a for loop.
Example of a scalar loop for SIMD
for (int i = 0; i < 1024; i++) {
c[i] = a[i] + b[i];
}In Rust, by default, the compiler will assume a target architecture. Using something too new will cause code to fail on older devices. The packed operation here operates on multiple data elements at once. The implication is that for looping stuff, we don’t need to loop as much.
This is a great use case for cases where loops operate over vectors of data.
Case Study: Stream VByte
This uses variable size bytes for integers which is harder but sometimes we can use less bits which is a performance improvement. We have control bits that tell us how many bytes we actually need to read. Then it seems we do some weird shuffle where we put decoded integers that we have read into known position in the SIMD register which is aligned.
On realistic input, this performs well. This is because:
- Control bytes are sequential and the CPU can always prefetch the next control byte since its location is predictable.
- Data bytes are also sequential
- The weird shuffling exploits the instruction set
- Control flow is regular
How this works:
The control stream encodes how many bytes each integer takes using 2-bit codes.
Control stream: 001011111001
Split into pairs: 00, 10, 11, 11, 10, 01
This gives us 6 integers with byte lengths: 1, 3, 4, 4, 3, 2 (we do the binary encoding +1).
Total bytes consumed: 1 + 3 + 4 + 4 + 3 + 2 = 17 bytes = 34 hex chars. The data stream is 50bc6386e9451dd1b3e5e7b71536589ab2 which is 34 hex chars.
Now we need to slice the data stream by reading the data stream in byte-pairs (each hex pair = 1 byte), consuming the lengths above:
- Integer 1 (1 byte):
50 - Integer 2 (3 bytes):
bc 63 86 - Integer 3 (4 bytes):
e9 45 1d d1 - Integer 4 (4 bytes):
b3 e5 e7 b7 - Integer 5 (3 bytes):
15 36 58 - Integer 6 (2 bytes):
9a b2
Stream-VByte stores little-endian integers, so we pad with leading zero bytes on the high end to fill 4 bytes:
50→00 00 00 50bc 63 86→00 bc 63 86e9 45 1d d1→e9 45 1d d1b3 e5 e7 b7→b3 e5 e7 b715 36 58→00 15 36 589a b2→00 00 9a b2