What is we recorded some data about the execution of a program, then fed it back to the compiler so it can predict better? This can decrease things like branch prediction misses.
We can do the same sort of thing for de-virtualization, and matching (typical values for a variable through a distribution).
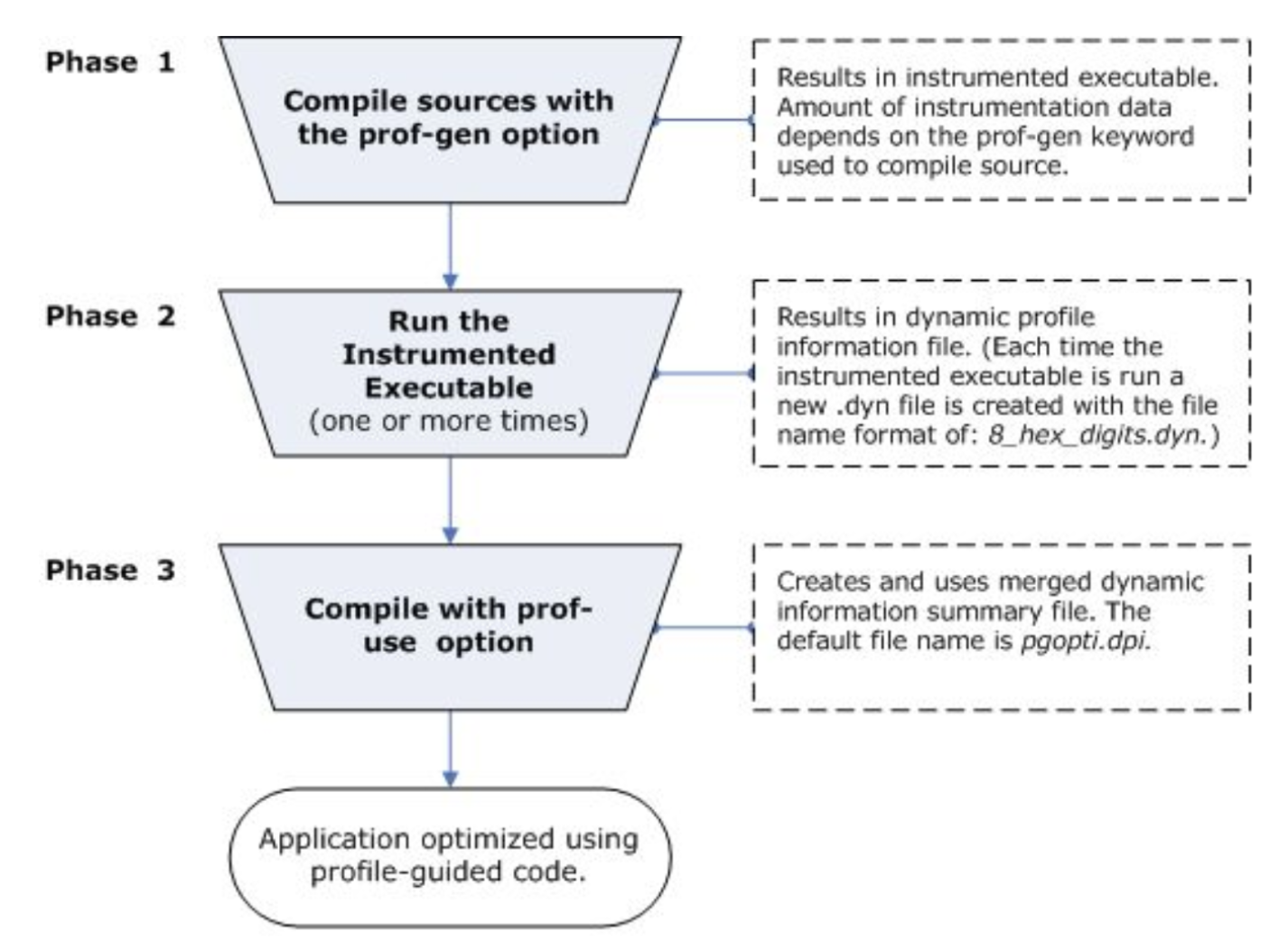
Multistep Compilation
To do all this:
- Compile with profiling
- Run to collect data
- Recompile with profiling to optimize
Measuring
The instrumentation that we use here are:
- Function entry probes
- Edge probes
- Value probes
Training
The point here is to figure out what matters and what does not. Therefore, running in real world scenarios is best. Spending time on performance critical sections. Use as many runs as possible. Exercising every part of the program is counter productive since it says that everything is important.
Recompile
Compile the program again using the training data so the compiler makes better decisions. We can reuse old training data as long as its still valid. We can also use user assigned weights for running different scenarios.
The compiler will use training data for:
- Full and partial inlining
- Function layout
- Speed and size decisions
- Basic block layout
- Code separation
- Virtual call separation
- Data separation
- Loop unrolling
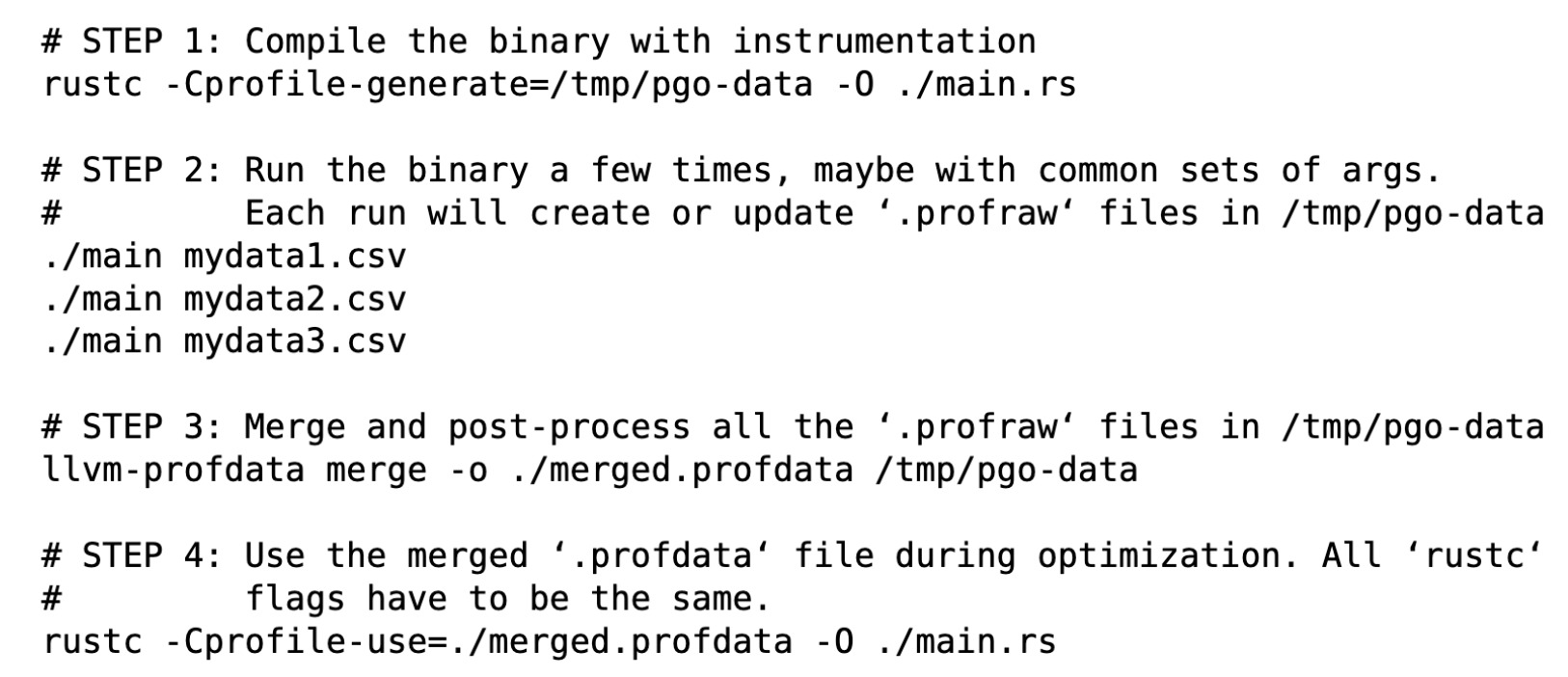
Most performance gains come from inlining decisions.