Flaky tests pass and fail on the same build.
Some tests have inherent non-determinism due to hardware, the environment, asynchronous properties, etc. Flaky tests waste developer effort.
You can easily test for flaky tests by running the same test 10 times and observing if there are inconsistencies between runs.
See Testing Outcomes
Quantifying Flakiness
- Measure the degree of flakiness
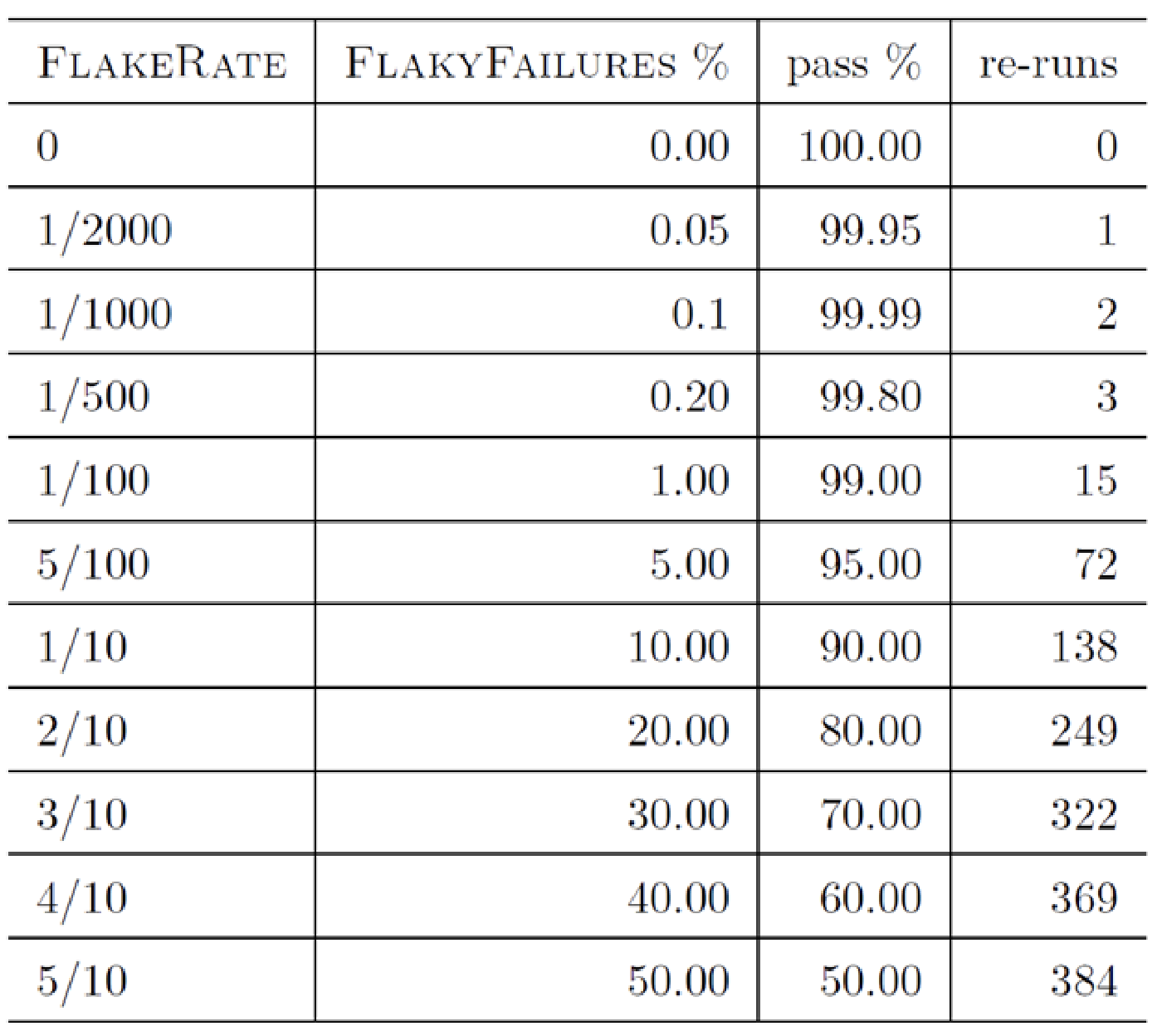
FlakeRate = Flakes / RunsAccuracy = (TP + TN) / RunsFlakeRate = (FP + FN) / Runs = 1 - Accuracy = (FailsNoFault+Slipthroughs) / RunsUsing this language, we can say that a test is 99% accurate or that is flakes 1/100 times. We can measure the flake rate over a period of time. However, this is very hard to do in practice.
- We want to establish a flake rate baseline on a stable build, this tells us which tests are flaky (tests that fail since the service is assumed to be stable and working well in production). Tests that pass true passes (TN).
StableAccuracy = (TP+TN) / Runs = (FailWithFaults + PassNoFault) / Runs = Passes / RunsStableFlakeRate = (FP + FN) / Runs = 1 - Accuracy = (FailNoFault + Slipthrough) / Runs = Fails / Runs- Figure out how flaky your test are
- Number of runs to have statically confident StableFlakeRate
- You cant just run one test run to determine this baseline, you want to do 666 runs for 99% confidence, or 1083 for 99.9% confidence, there’s a formula to calculate this.
In general, flaky tests add extra runs which add extra costs.
Prioritizing
- Likelihood of change in stable state (binomial distribution)
- Prioritization re-runs to find instabilities (probability set of runs)
Probability
Using a binomial distribution:
- We can find the probability of getting f failures with r test runs
- tells us the likelihood of getting the set of test results from re-runs
- Flake Rate is calculated from a stable build and estimated by test failure rate
- Determine if the rate has changed at statistically significant levels
- Given a hypothesized pass rate, we can do things like p-value testing to see if our null hypothesis holds
- We want to re-run tests with the least likely outcome
- Stop when result is statistically significant or no more re-runs are available
- Will quickly find the tests that have become unstable
Using a Bernoulli trial:
, let p be the probability of success in a Bernoulli trial, and q be the probability of failure.
- There are n independent trials
- calculates the probability of exactly k successes.
- This counts the number of ways to form an unordered collection of k items from a collection of n distinct items

Summary
Tests no longer have a binary outcome. They become unstable relative to a baseline build FlakeRate
In general, we want to prioritize tackling tests that are likely to be flaky.
Noise vs Signal
- In a signal, the test starts failing much more than expected
- Likely someone changed the code and there is a fault
- In a noise, the test fails at expected levels. This is likely just normal interference
Algorithm to find changes in stable test failure rates
- Run each test once
- Calculate
- Order tests by
- Run the tests with the lowest
- Investigate tests that show highly unlikely fail rates (unstable)
- Go to step 5 until no more tests are budgeted
In general, we establish a testing queue that we tackle based on test prioritizations (test the most unlikely outcome, updates its probability and put it back into the queue depending on its new outcome, repeat until you are out of budget). If there is a significant deviation between the current and historic test distribution, this is an indicator of something bad.
Should you fix flaky tests?
- If the behaviour of the system is stable, maybe not
- Making a test less flaky will make them less noisy
- The tradeoff is the cost to fix the tests vs the cost of testing